In our previous blog post we introduced the Interrogizer project. Interrogizer is a logic analyser, which means it samples binary signals and sends the samples to a host computer as fast as possible.
Interrogizer runs one of the cheapest stm32 microcontrollers. We are running it at a clock rate of 48MHz and would like to reliably send samples down the 12Mb/s USB link. This does not leave many cycles to process each USB packet.
This blog post explains how we have measured our performance bottlenecks and what we have done about them.
Profiling on embedded projects
In hosted (non-embedded) software, one can measure performance bottlenecks using a profiler such as gprof. This can measure what proportion of the total execution time is spent in each function in a program. This sort of thing can't be done on an embedded project because the hardware and software involved are too minimal.
Our solution was to toggle GPIO pins to indicate the current state of the firmware. We could then measure these pins using another logic analyser or an oscilloscope and use these measurements to determine the time spent in different states.
Toggling a GPIO pin does not lead to too much measurement overhead. On stm32 the GPIO pins are memory mapped: to toggle a single GPIO pin, the CPU only needs to write to the right bit of the memory address corresponding to the GPIOx_BSRR register [1]. This will only take a few cycles. In our case the dominant factor is the overhead in the function calls involved.
For example, to measure the iteration speed of the main loop of the firmware we toggled a spare GPIO with each iteration of the loop. Next we measured the frequency of this GPIO pin. The frequency of the loop iteration is double the frequency of the GPIO because it takes two iterations of the loop to toggle the pin high and then low.
[1] STM32F0 Reference Manual Section 8.4.7
The original implementation
The initial prototype was as simple as possible. A timer generated interrupts at the sampling frequency. When this interrupt fired, the interrupt service routine would set a flag and copy a reading of the state of the input pins to a temporary buffer. Outside of interrupt context, the firmware would loop continually checking for new USB packets and copying new samples from the temporary buffer into a larger buffer. When that larger buffer became full, the whole sample buffer would be sent to the host PC over USB.

In this oscilloscope capture:
-
Channel 1 (top) is high while the CPU is instructing the USB hardware to send a packet (the actual time spent sending the packet is longer, as we will see later)
-
Channel 2 (upper middle) toggles with each iteration of the main loop
-
Channel 3 (lower middle) toggles when the main loop reads a sample
-
Channel 4 (bottom) toggles when the timer interrupt handler is invoked
At this sample frequency, every iteration of the main loop records a sample. The main loop operates at around 80kHz (we have to double the frequency of the waveform because the pin is toggled once for each iteration). Therefore we can't record samples any faster than 80kHz (despite the sampling interrupt on Channel 4 attempting 200kHz).
The bottleneck here is the CPU. To achieve higher sampling rates we needed to offload some of this work from the CPU to supporting peripherals in the stm32f0.
DMA
What does the DMA controller do?
Direct memory access (DMA) is used in order to provide high speed data transfer between peripherals and memory as well as memory to memory. Data can be quickly moved by DMA without any CPU actions. This keeps CPU resources free for other operations.
STM32F0 Reference Manual section 10.1
In other words, the DMA controller can arrange to copy data in memory without the involvement of the CPU. This leaves the CPU available to do other things.
In our case, the DMA controller can automate the reading of GPIO pins into a memory buffer. The CPU then only needs to get involved to transmit that sample buffer over USB. In the Interrogizer USB protocol there are 63 samples per packet and so the CPU only needs to do work at 1/63 of the sample rate. This is a massive improvement upon the previous implementation which saw the CPU needing to keep up with every sample.
How does it work?
When triggered, the DMA controller will read from a "peripheral address" (optionally incrementing that address), writing to a specified "memory address" (optionally incremented). This will continue for a specified length before either stopping or looping back to the starting addresses. Interrupts may be generated at the halfway point and when the transfer is completed (when looping back to the starting addresses). The memory operation widths can be configured independently for the read and write operations.
There are several modes for triggering the DMA operation. In "peripheral to memory" mode the DMA controller will perform each read/write when told to do so by another microcontroller peripheral. For example, the analogue to digital converter can trigger a DMA read each time new samples are available. Another is "memory to memory" mode. In this mode, DMA will copy from one memory address to another as fast as possible, without being instructed to do so by another peripheral. Finally, there is also a "memory to peripheral" mode, where the DMA controller will copy from a memory buffer to a peripheral, when that peripheral says it is ready (e.g. copying from a buffer to serial whenever the serial peripheral is ready to transmit new data).
For Interrogizer we put the DMA controller in "peripheral to memory" mode, triggering it using a timer. As in the previous implementation, the timer was configured to generate events at the intended sample rate. For the DMA implementation we got rid of the interrupt handler for the timer and instead configured the timer to generate a DMA request using the TIM_DIER_CCnDE bit of the DMA/interrupt enable register for the timer.
On the output side, Interrogizer needed concurrent access to the output samples for both the DMA writing new samples and the CPU queuing samples to be sent over USB. The normal way to do this would be to use double buffering. This is where there are two buffers used for samples, with the DMA controller alternating between these two buffers and the CPU only using the buffer not currently written to by the DMA controller. Unfortunately the DMA controller in our chip does not support real double buffering (but higher end stm32 microcontrollers do support this). However, we can simulate almost the same thing using the half-transfer interrupt.
In this scheme we used DMA to continually fill and refill a buffer twice as large as a USB packet. The half- and full-transfer interrupts generated by the DMA controller determine which half of the buffer is currently written to by the DMA controller. The CPU may then read samples from the other half of the buffer. Compared to a truly double-buffered system this only requires slightly more CPU overhead for the half-transfer interrupt.
Here we have an oscilloscope capture of 200kHz sampling using DMA transfers:
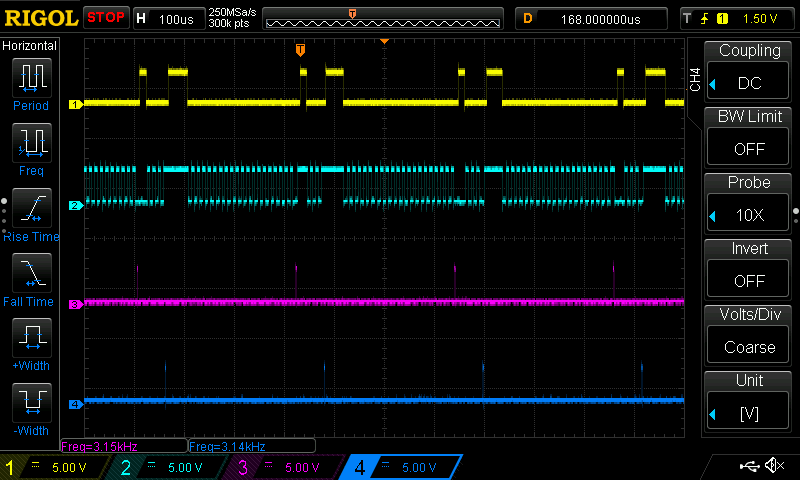
In this capture:
-
Channel 1 (top) is high while the CPU is instructing the USB hardware to send a packet
-
Channel 2 (upper middle) toggles with each iteration of the main loop
-
Channel 3 (lower middle) is high while handling a half- or full-transfer DMA interrupt for reading GPIO Port A
-
Channel 4 (bottom) is high while handling a half- or full-transfer DMA interrupt for GPIO Port B
The measurements by the oscilloscope show that a sample packet is ready to be sent approximately every 3.15kHz. There are 63 samples in the packet so the sampling frequency is about 198kHz (the discrepancy from the intended 200kHz is likely down to measurement error).
We can see from channel 2 that the CPU has no trouble keeping up with 200kHz sampling now.
Channel 1 shows that two sample packets are sent for every 63 samples. One of these is for GPIO Port A and the other for GPIO Port B. We can see from the trace that the second packet takes longer than the first. Both packets are the same size. The reason for the delay is that the CPU is blocking waiting for the USB hardware to be ready to send another packet.
Expanding this a little, when the CPU tries to send the first packet, the USB hardware is not using the transmission buffer for that endpoint so the CPU can immediately copy the packet into the USB peripheral memory then set a flag telling the hardware to begin sending the packet. When the CPU tries to send the second packet, it finds that the transmission buffer (containing the first packet) is still in use by the USB hardware. Therefore, the CPU has to wait until the buffer is available before it can begin copying in the second packet.
USB congestion is much more obvious at higher sample rates. For example at 500kHz with both ports enabled:

The channels here are the same as on the previous trace.
In this trace we see that the CPU is always tied up waiting for and feeding packets into the USB hardware. This leads to some sample packets getting missed.
The new bottleneck is the USB connection.
USB Double buffering
As alluded to in the previous section, there's a gap where the USB hardware is not sending a packet while it waits for the CPU to copy in a new USB packet. This makes it impossible to get the full bandwidth out of the USB connection.
The solution is to use the double buffered mode of the USB peripheral. In this mode, each endpoint uses two packet buffers, with the USB hardware alternating between them. Similar to the big buffer split in half for DMA, the USB double buffering allows the CPU to be writing into one buffer while the USB hardware sends the other buffer. For a high enough sample rate this allows the USB hardware to send sample packets as often as the bus allows.
We had high hopes for USB double buffering but it turned out not to make a significant difference to the time taken to send USB packets. This was because at high sample rates there was already very little delay between the availability of a sample buffer and the availability of USB hardware to send that buffer. Furthermore, the time taken for the CPU to copy the packet buffer to the USB endpoint buffer was negligible compared to the time taken to transmit the packet over the USB 1.1 link.
Where USB double buffering could have been useful would be for DMA to copy directly from GPIO into the USB buffer. This would halve memory traffic and leave the CPU free for other things. We decided not to implement this for Interrogizer because the bottleneck is on the USB bus not CPU or memory bandwidth.
The biggest problem which prevented 500kHz sampling (even for one channel) was occasional USB transactions which took much longer than usual. One can be seen here
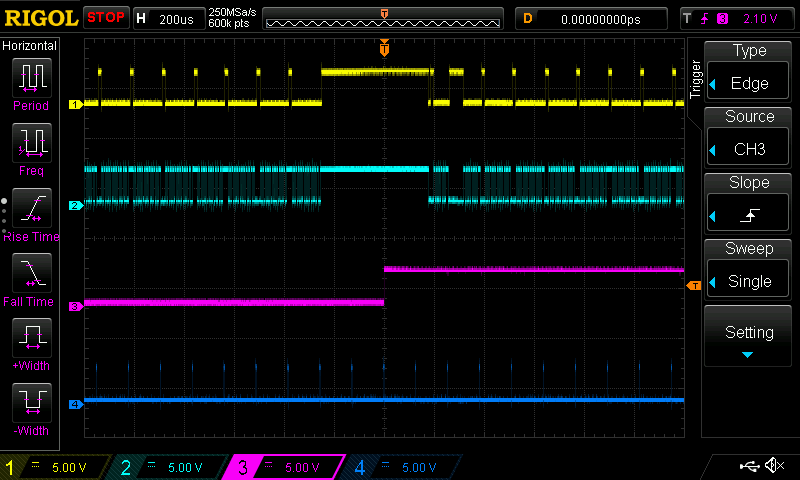
The channels here are the same as the previous two traces except for channel 3 which is asserted when the firmware detects it has fallen behind when sending samples.
Here we can see that (from the CPU's perspective) most of the packets are sent very quickly but the one triggering the error condition took significantly longer. We suspect this rare, very long USB transaction was either down to a packet retransmission or the bulk endpoint being preempted by the control endpoint.
From traces such as these we can see that we are at the limit of the data throughput we can get from USB 1.1. This is about what one might expect:
-
USB 1.1 has a theoretical transfer rate of 12Mb/s = 1.5MB/s
-
There is a 10% bandwidth reservation for control endpoints, leaving 1.35MB/s
-
Our packets include one opcode byte and 63 sample bytes. The overhead in USB adds another 19 bytes to the packet
-
Therefore, sampling one port at 500kHz requires a bandwidth of approximately 660kB/s. This is approximately half of the available bandwidth so it would make sense that even a single retransmission could cripple the transfer (by the time the latency for the NAK packet leading to the retransmission is considered)
These long delays were frustrating because 500kHz for one port very nearly works. But it would not be acceptable to randomly drop sample packets and so this frequency cannot be used.
Conclusion
This article discussed methods for improving performance of stm32 microcontroller projects without resorting to purchasing more expensive hardware. While these microcontrollers feature low clock rates, they are rich in peripherals (such as DMA) which can be used to offload work from the slow CPU.
Other Content
- Podcast: Embedded Insiders with John Ellis
- To boldly big-endian where no one has big-endianded before
- How Continuous Testing Helps OEMs Navigate UNECE R155/156
- Codethink’s Insights and Highlights from FOSDEM 2025
- CES 2025 Roundup: Codethink's Highlights from Las Vegas
- FOSDEM 2025: What to Expect from Codethink
- Codethink Joins Eclipse Foundation/Eclipse SDV Working Group
- Codethink/Arm White Paper: Arm STLs at Runtime on Linux
- Speed Up Embedded Software Testing with QEMU
- Open Source Summit Europe (OSSEU) 2024
- Watch: Real-time Scheduling Fault Simulation
- Improving systemd’s integration testing infrastructure (part 2)
- Meet the Team: Laurence Urhegyi
- A new way to develop on Linux - Part II
- Shaping the future of GNOME: GUADEC 2024
- Developing a cryptographically secure bootloader for RISC-V in Rust
- Meet the Team: Philip Martin
- Improving systemd’s integration testing infrastructure (part 1)
- A new way to develop on Linux
- RISC-V Summit Europe 2024
- Safety Frontier: A Retrospective on ELISA
- Codethink sponsors Outreachy
- The Linux kernel is a CNA - so what?
- GNOME OS + systemd-sysupdate
- Codethink has achieved ISO 9001:2015 accreditation
- Outreachy internship: Improving end-to-end testing for GNOME
- Lessons learnt from building a distributed system in Rust
- FOSDEM 2024
- QAnvas and QAD: Streamlining UI Testing for Embedded Systems
- Outreachy: Supporting the open source community through mentorship programmes
- Using Git LFS and fast-import together
- Testing in a Box: Streamlining Embedded Systems Testing
- SDV Europe: What Codethink has planned
- How do Hardware Security Modules impact the automotive sector? The final blog in a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part two of a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part one of a three part discussion
- Automated Kernel Testing on RISC-V Hardware
- Automated end-to-end testing for Android Automotive on Hardware
- GUADEC 2023
- Embedded Open Source Summit 2023
- RISC-V: Exploring a Bug in Stack Unwinding
- Adding RISC-V Vector Cryptography Extension support to QEMU
- Introducing Our New Open-Source Tool: Quality Assurance Daemon
- Achieving Long-Term Maintainability with Open Source
- FOSDEM 2023
- PyPI Security: How to Safely Install Python Packages
- BuildStream 2.0 is here, just in time for the holidays!
- A Valuable & Comprehensive Firmware Code Review by Codethink
- GNOME OS & Atomic Upgrades on the PinePhone
- Flathub-Codethink Collaboration
- Codethink proudly sponsors GUADEC 2022
- Tracking Down an Obscure Reproducibility Bug in glibc
- Full archive